Step-by-step: Scraping Epsiode IMDb Ratings
There are tons of tutorials out there that teach you how to scrape movie ratings from IMDb, but I haven’t seen any about scraping TV series episode ratings. So for anyone wanting to do that, I’ve created this tutorial specifically for it. It’s catered mostly to beginners to web scraping since the steps are broken down. If you want the code without the breakdown you can find it here.
There is a wonderful DataQuest tutorial by Alex Olteanu that explains in-depth how to scrape over 2000 movies from IMDb, and it was my reference as I learned how to scrape these episodes.
Since their tutorial already does a great job at explaining the basics of identifying the URL structure and understanding the HTML structure of a single page, I’ve linked those parts and recommend you read them if you aren’t already familiar because I won’t be explaining them here.
In this tutorial I will not be redundant in explaining what they already did1; instead, I’ll be doing many similar steps, but they will be specifically for taking episode ratings (same for any TV series) instead of movie ratings.
Breaking it down
First, you’ll need to navigate to the series of your choice’s season 1 page that lists all of that season’s episodes. The series I will be using is Community. It should look like this:
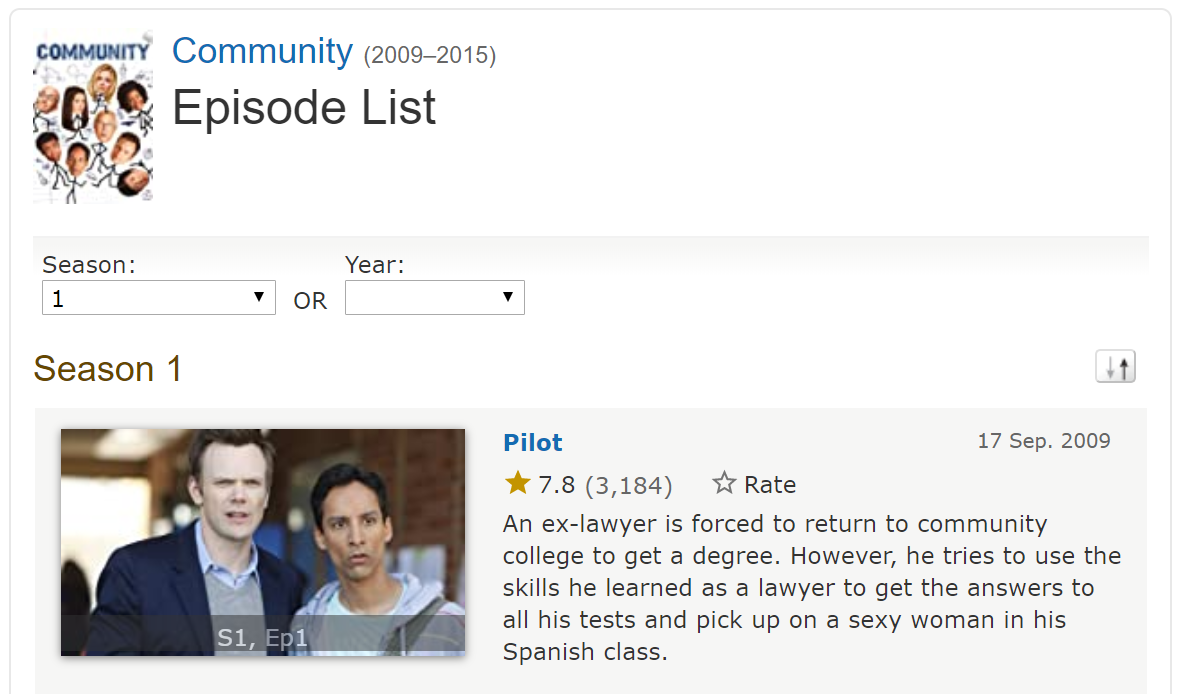
Get the url of that page. It should be structured like this:
http://www.imdb.com/title/tt1439629/episodes?season=1
Highlighted is the part that is the show’s ID and will be different for you if you’re not using Community.
First, we will request from the server the content of the web page by using get(), and store the server’s response in the variable response and look at the first few lines. We can see that inside response is the html code of the webpage.
from requests import get
url = 'https://www.imdb.com/title/tt1439629/episodes?season=1'
response = get(url)
print(response.text[:250])
<!DOCTYPE html>
<html
xmlns:og="http://ogp.me/ns#"
xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="apple-itunes-app" content="app-id=342792525, app-argument=imdb:///title/tt1439629?src=mdot">
Use BeautifulSoup to parse the HTML content
Next, we’ll parse response.text by creating a BeautifulSoup object, and assign this object to html_soup. The html.parser argument indicates that we want to do the parsing using Python’s built-in HTML parser.
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(response.text, 'html.parser')
type(html_soup)
bs4.BeautifulSoup
This part onwards is where the code will differ from the movie example.
The variables we will be getting are:
- Episode title
- Episode number
- Airdate
- IMDb rating
- Total votes
- Episode description
Let’s look at the container we’re interested in. As you can see below, all of the info we need is in <div class="info" ...> </div>:
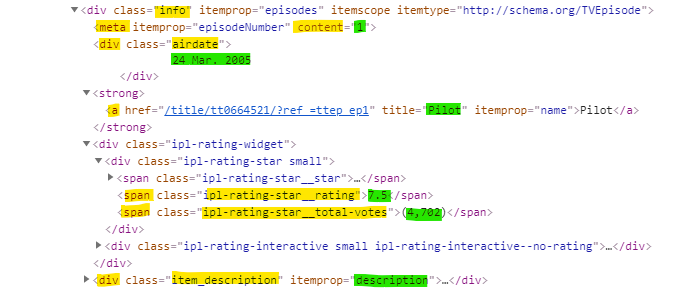
In yellow are the tags/parts of the code that we will be calling to get to the data we are trying to extract, which are in green.
We will grab all of the instances of <div class="info" ...> </div> from the page; there is one for each episode.
episode_containers = html_soup.find_all('div', class_='info')
find_all() returned a ResultSet object –episode_containers– which is a list containing all of the 25 <div class="info" ...> </div>s.
Extracting each variable that we need
Read this part of the DataQuest article to understand how calling the tags works.
Here we’ll see how we can extract the data from the episode_containters for each episode.
episode_containters[0] calls the first instance of <div class="info" ...> </div>, i.e. the first episode. After the first couple of variables, you will understand the structure of calling the contents of the html containers.
Episode title
For the title we will need to call title attribute from the <a> tag.
episode_containers[0].a['title']
'Pilot'
Episode number
The episode number in the <meta> tag, under the content attribute.
episode_containers[0].meta['content']
'1'
Airdate
Airdate is in the <div> tag with the class airdate, and we can get its contents the text attribute, afterwhich we strip() it to remove whitespace.
episode_containers[0].find('div', class_='airdate').text.strip()
'17 Sep. 2009'
IMDb rating
The rating is is in the <div> tag with the class ipl-rating-star__rating, which also use the text attribute to get the contents of.
episode_containers[0].find('div', class_='ipl-rating-star__rating').text
'7.8'
Total votes
It is the same thing for the total votes, except it’s under a different class.
episode_containers[0].find('span', class_='ipl-rating-star__total-votes').text
'(3,187)'
Episode description
For the description, we do the same thing we did for the airdate and just change the class.
episode_containers[0].find('div', class_='item_description').text.strip()
'An ex-lawyer is forced to return to community college to get a degree. However, he tries to use the skills he learned as a lawyer to get the answers to all his tests and pick up on a sexy woman in his Spanish class.'
Final code– Putting it all together
Now that we know how to get each variable, we need to iterate for each episode and each season. This will require two for loops. For the per season loop, you’ll have to adjust the range() depending on how many seasons are in the show you’re scraping.
The output will be a list that we will make into a pandas DataFrame. The comments in the code explain each step.
# Initializing the series that the loop will populate
community_episodes = []
# For every season in the series-- range depends on the show
for sn in range(1,7):
# Request from the server the content of the web page by using get(), and store the server’s response in the variable response
response = get('https://www.imdb.com/title/tt1439629/episodes?season=' + str(sn))
# Parse the content of the request with BeautifulSoup
page_html = BeautifulSoup(response.text, 'html.parser')
# Select all the episode containers from the season's page
episode_containers = page_html.find_all('div', class_ = 'info')
# For each episode in each season
for episodes in episode_containers:
# Get the info of each episode on the page
season = sn
episode_number = episodes.meta['content']
title = episodes.a['title']
airdate = episodes.find('div', class_='airdate').text.strip()
rating = episodes.find('span', class_='ipl-rating-star__rating').text
total_votes = episodes.find('span', class_='ipl-rating-star__total-votes').text
desc = episodes.find('div', class_='item_description').text.strip()
# Compiling the episode info
episode_data = [season, episode_number, title, airdate, rating, total_votes, desc]
# Append the episode info to the complete dataset
community_episodes.append(episode_data)
Making the dataframe
import pandas as pd
community_episodes = pd.DataFrame(community_episodes, columns = ['season', 'episode_number', 'title', 'airdate', 'rating', 'total_votes', 'desc'])
community_episodes.head()
| season | episode_number | title | airdate | rating | total_votes | desc | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Pilot | 17 Sep. 2009 | 7.8 | (3,187) | An ex-lawyer is forced to return to community ... |
| 1 | 1 | 2 | Spanish 101 | 24 Sep. 2009 | 7.9 | (2,760) | Jeff takes steps to ensure that Brita will be ... |
| 2 | 1 | 3 | Introduction to Film | 1 Oct. 2009 | 8.3 | (2,696) | Brita comes between Abed and his father when s... |
| 3 | 1 | 4 | Social Psychology | 8 Oct. 2009 | 8.2 | (2,473) | Jeff and Shirley bond by making fun of Britta'... |
| 4 | 1 | 5 | Advanced Criminal Law | 15 Oct. 2009 | 7.9 | (2,375) | Señor Chang is on the hunt for a cheater and t... |
Looks good! Now we just need to clean up the data a bit.
Data Cleaning
Converting the total votes count to numeric
First, we create a function that uses replace() to remove the ‘,’ , ‘(', and ‘)’ strings from total_votes so that we can make it numeric.
def remove_str(votes):
for r in ((',',''), ('(',''),(')','')):
votes = votes.replace(*r)
return votes
Now we apply the function, taking out the strings, then change the type to int using astype()
community_episodes['total_votes'] = community_episodes.total_votes.apply(remove_str).astype(int)
community_episodes.head()
| season | episode_number | title | airdate | rating | total_votes | desc | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Pilot | 17 Sep. 2009 | 7.8 | 3187 | An ex-lawyer is forced to return to community ... |
| 1 | 1 | 2 | Spanish 101 | 24 Sep. 2009 | 7.9 | 2760 | Jeff takes steps to ensure that Brita will be ... |
| 2 | 1 | 3 | Introduction to Film | 1 Oct. 2009 | 8.3 | 2696 | Brita comes between Abed and his father when s... |
| 3 | 1 | 4 | Social Psychology | 8 Oct. 2009 | 8.2 | 2473 | Jeff and Shirley bond by making fun of Britta'... |
| 4 | 1 | 5 | Advanced Criminal Law | 15 Oct. 2009 | 7.9 | 2375 | Señor Chang is on the hunt for a cheater and t... |
Making rating numeric instead of a string
community_episodes['rating'] = community_episodes.rating.astype(float)
Converting the airdate from string to datetime
community_episodes['airdate'] = pd.to_datetime(community_episodes.airdate)
community_episodes.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 110 entries, 0 to 109
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 season 110 non-null int64
1 episode_number 110 non-null object
2 title 110 non-null object
3 airdate 110 non-null datetime64[ns]
4 rating 110 non-null float64
5 total_votes 110 non-null int32
6 desc 110 non-null object
dtypes: datetime64[ns](1), float64(1), int32(1), int64(1), object(3)
memory usage: 5.7+ KB
community_episodes.head()
| season | episode_number | title | airdate | rating | total_votes | desc | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Pilot | 2009-09-17 | 7.8 | 3187 | An ex-lawyer is forced to return to community ... |
| 1 | 1 | 2 | Spanish 101 | 2009-09-24 | 7.9 | 2760 | Jeff takes steps to ensure that Brita will be ... |
| 2 | 1 | 3 | Introduction to Film | 2009-10-01 | 8.3 | 2696 | Brita comes between Abed and his father when s... |
| 3 | 1 | 4 | Social Psychology | 2009-10-08 | 8.2 | 2473 | Jeff and Shirley bond by making fun of Britta'... |
| 4 | 1 | 5 | Advanced Criminal Law | 2009-10-15 | 7.9 | 2375 | Señor Chang is on the hunt for a cheater and t... |
Great! Now the data is tidy and ready for analysis/visualization.
Let’s make sure we save it:
community_episodes.to_csv('Community_Episodes_IMDb_Ratings.csv',index=False)
And that’s it, I hope this was helpful! Feel free to comment or DM me for any edits or questions.
The links for my github repository for this project and the final Community ratings dataset can be found in the links at the top of this page.

-
In the tutorial, they have extra sections where they control the crawl-rate & monitor the loop as it’s still going, but we won’t do that here because series’ have much less episodes (they scraped 2000+ movies) so that’s not necessary. ↩︎